



Creating new Service Principal for Databricks (work in progress)
Planning new Service Principal (SP)
This information should obtained before hand and mostly should be presented in the request or task description.
-
Requestor privileges (not needed for task or request)
Requestor will need to have admin privileges in Databricks environment in order to add SP and assign it to a group.
-
Name of new Service Principal
Name should use the naming convention of <dept name>-SVC-<project>-<function>-<environment>
(see examples in request template below)
-
Group assignment for new Service Principal
Need to determine if SP can be added to an existing group
If a new group is needed will this group need its own workspace and/or catalog
-
Saving SP credentials and information
Determine where the SP secret and client_id information will be located at.
It is recommended to use a Azure Key Vault, the Azure subscription and resource group location of the Key Vault will be needed.
Request support from Washington University Information Technology (WUIT) team
First step is to request that WUIT create an EntraID(Azure active directory) account for the new SP
Link to Form: Service NOW CSP - General Access & Security
Request example/template for Service NOW
The below template can be modified for the new SP by just altering the name in the details section and then the requestors name at the end and submitted with the general access request made to WUIT.
I am requesting a new service principal in EntraID (AD), which would be sync'd into our Azure subscription. This SP would be used within our WUSM Datalake as a user, and be given access to needed objects in our Datalake.
Details:
1. Name: I2DB-SVC-RDC-ETL-DEV
2. Type: Service Principal
3. Example SP in use today( I2DB-SVC-MDCLONE-ETL-DEV ) - Would be same setup.
I would need the client secret as we use that to generate a PAT (Personal Access Token) for which the consuming application uses as its password into our datalake.
This request is similar to ticket RITM0328535, if there are any question contact me via Teams or Email.
Thanks,
Warren ThomasAdding Service principal to Databricks
Once WUIT has completed the general access request and sent the requestor the SP EntraID credentials the
If this is for a Databricks group that doesn't exist yet and needs its own workspace an/or catalog please make a request for the Platform Engineering team
Either Ian Lackey(lackey_i@wustl.edu) or Christopher Lundeberg(lundeberg@wustl.edu) are the points of contact for Platform Engineering (PE).
Otherwise, note which Databricks group the new service principal will need to be added for the following steps.
Adding new Service Principal to Databricks Environment
- Link to Databricks Accounts: navigate to the databricks account console-> Service principal tab

- press the app service principal button (shown in above image)
- Select Microsoft Entra ID managed and fill in service principal information provided by WUIT and press add button. The Microsof Entra application ID is the same as Client ID provided by WUIT.
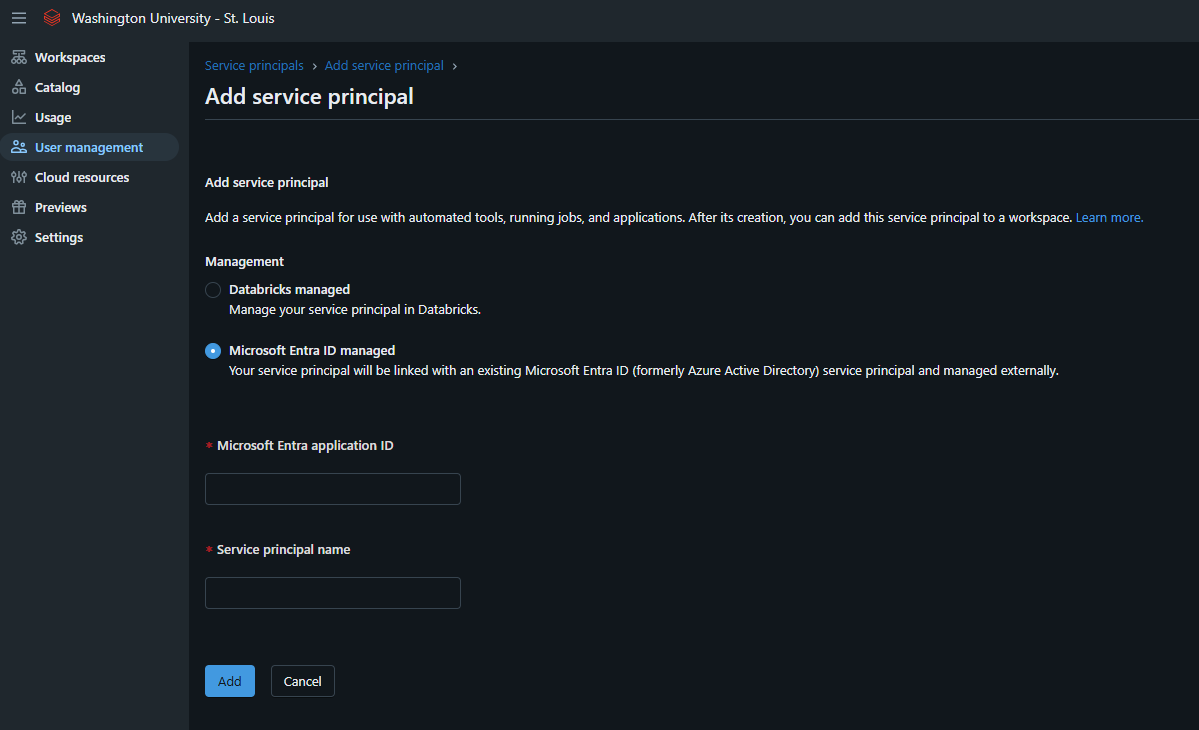
- klsfgkldsfg
high level steps for adding SP to databrick env
- WUIT request (documented above)
- if this is for a new group, request that PE add group to Databricks platform? (documented above)
- add SP to databricks in https://accounts.azuredatabricks.net/ (documented above)
- add SP to new or existing group https://accounts.azuredatabricks.net/
- confirm group and SP in databricks
- create SP api token
- store client id,secret and api token in Azure key vault
REview with Chris Lundenburg
adding SP to databrick env
-
WUIT request (documented)
-
add working group and assigning to a cluster in databasin if needed
-
push SP to work space by adding permission to wusm-prod-adb workspace
-
add SP to databricks in https://accounts.azuredatabricks.net/
-
add SP to group https://accounts.azuredatabricks.net/
-
confirm group and SP in databricks
-
create SP api token
-
store client id,secret and api token in Azure key vault
-
setup privileges in databricks
make sure under Databricks the service principal can create clusters
service principal need to be granted USE CATALOG for the cleansed catalog via ADO Entra ID (PE request at this time).
Might be able to be request at time of SP creation? -
setup devops privileges if using git repos
troubleshooting tips for databricks connectors(w/Ian):
-
find the HTTP path for the sql warehouse you would like to use
-
ensure the account has access to the SQL warehouse
-
ensure the account has access to the catalog you are providing to the connector
-
ensure the port is set to 443
-
check errors in run_jobs if databasin fails